
This Video from Stanford CS231n explains it really well, and the basic idea is that we want to maximize the log data likelihood, which can be expressed as
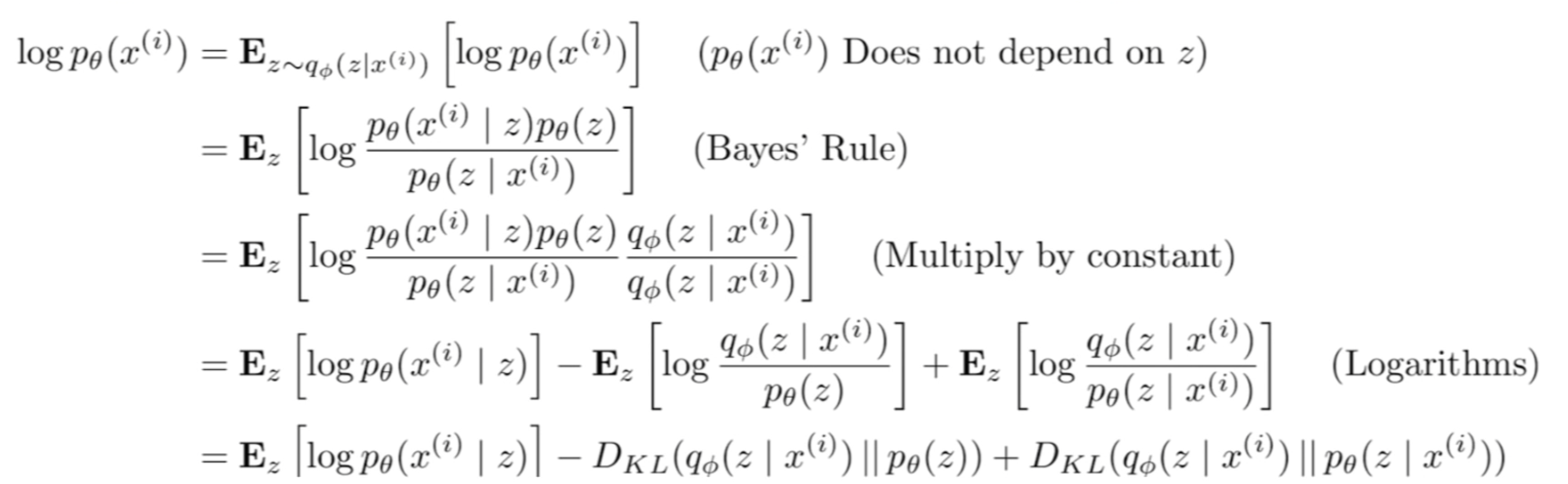
-
In the equation above, the first step follows because our training data likelihood does not depend on latent variable, and thus taking the expectation wrt latent variable does not change the log data likelihood.
-
In the last step, the first term is the decoder, which is the probability of getting a certain training data conditioned on the latent variable. The second is the KL divergence between the encoder and the prior of latent variable, basically we want the distribution of z we get out of the encoder to be similar to a Gaussian prior.
-
The last term, which is the KL divergence of our encoder wrt the true posterior distribution of z given x, is intractable. All we know is that this KL term is non-negative.
-
Thus, maximizing the log data likelihood corresponds to maximizing its lower bound, which are the first two terms. The first term should increase, which means we want to reconstruct our training data, while the second term should decrease, which means we want our z distribution to also be Gaussian.
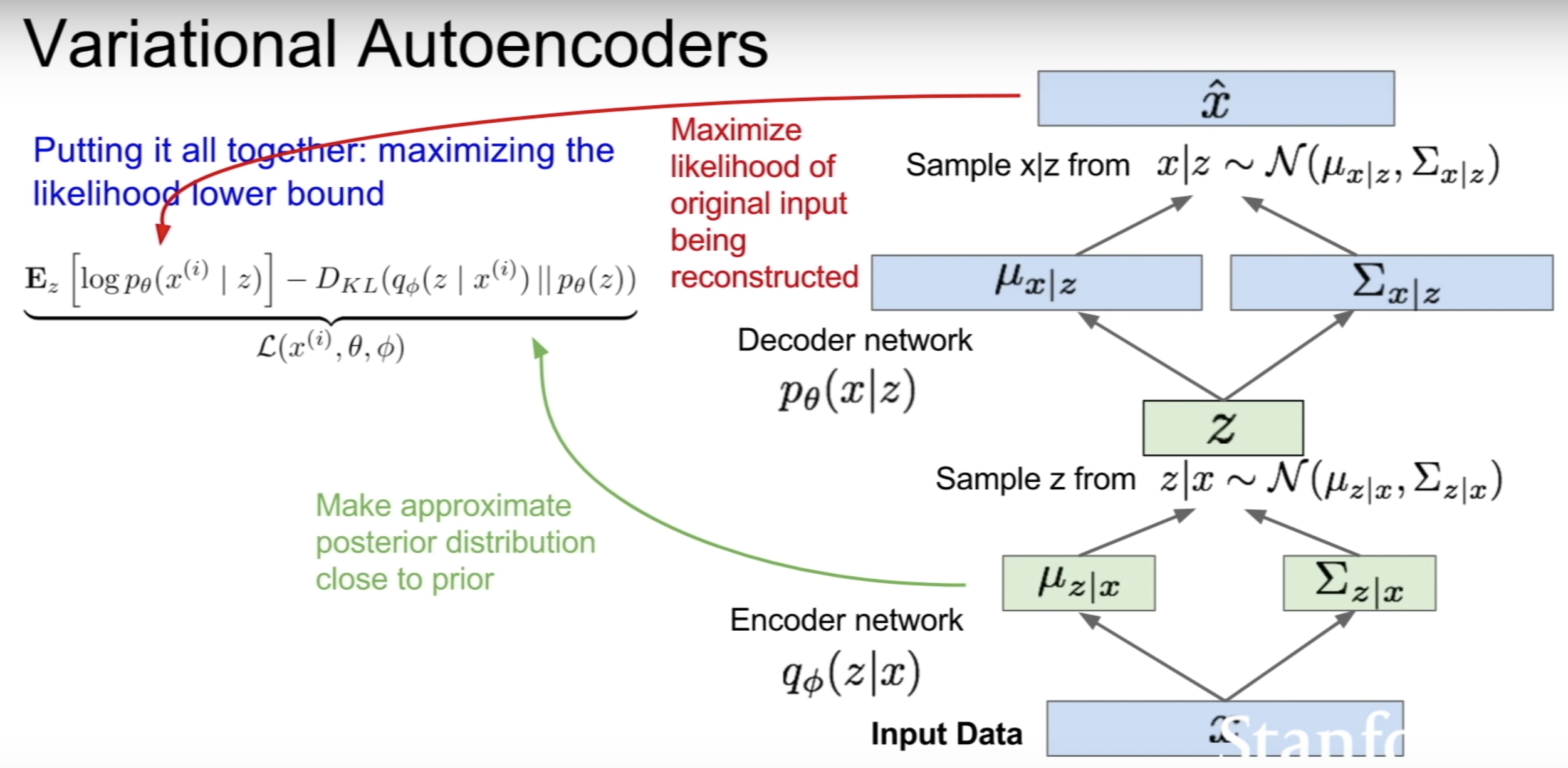
The slide above summarizes the training process.
- First we have some input data x, we can train the encoder to obtain the conditional mean and covariance for z.
- Then we sample z from the Gaussian, and pass it to our decoder network which gives the conditional mean and covariance for x, and we can sample from this to get back x.
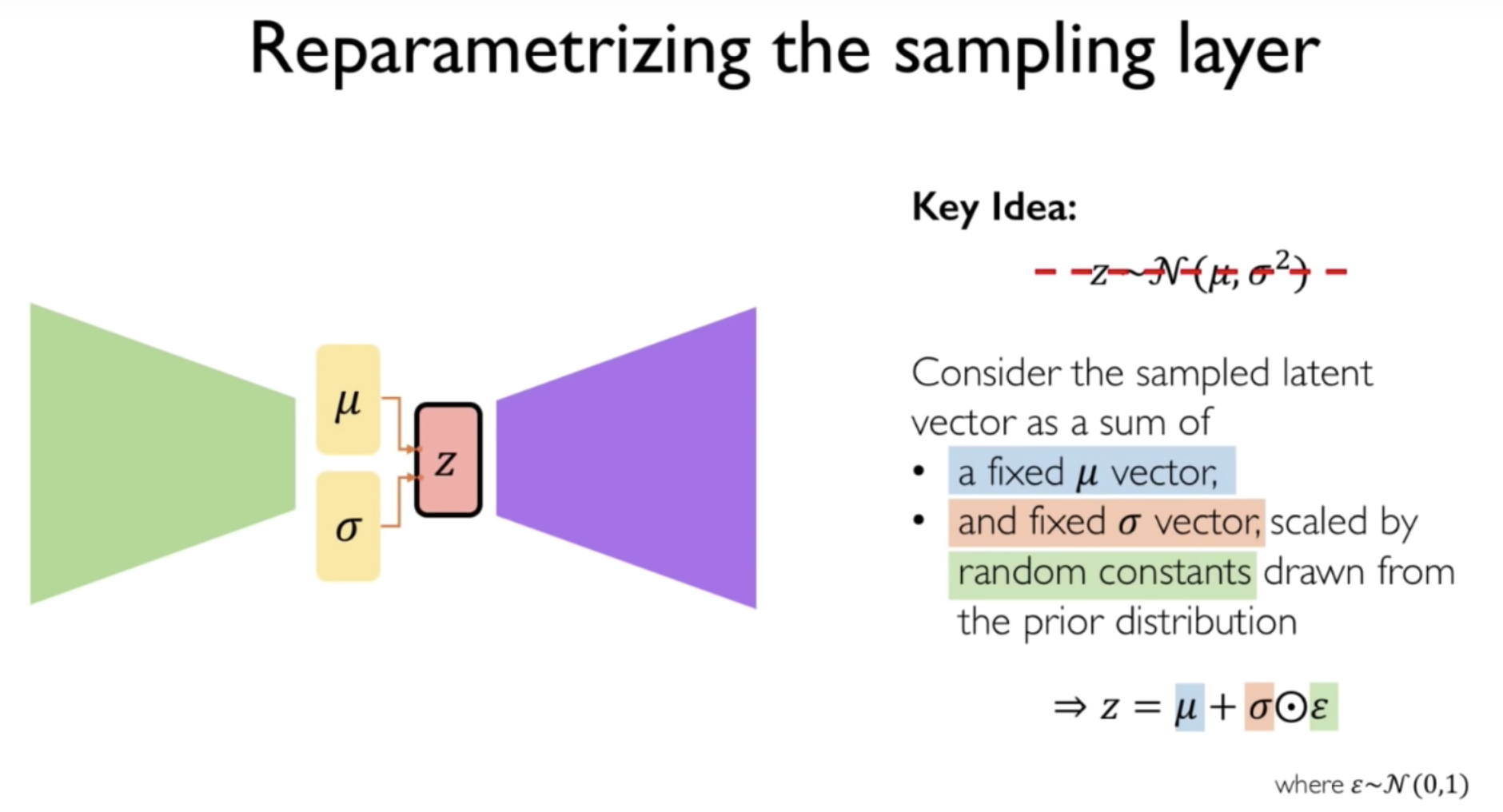
One issue is how to train the VAE. As explained in a slide in this video, the mean and std of z are static, but std is also scaled by a random constant generated from the Normal distribution.

A related generation model is GAN, which does not model the distribution of latent space directly. Instead we are trying to sample from the latent space, by first sampling from a noise and then transform this sample to the latent space. Since we are not training on the latent space, we don’t have the semantic meaning there as in VAE.
As shown in the cost function above, the generator is trying to minimize the cost, by generating samples to fool the discriminator (probability of fake data = 1), while the discriminator is trying to maximize the above cost by rejecting the samples generated by the generator (probability of real data = 1, probability of fake data = 0), and thus when training the discriminator we use gradient ascend.